应用示例
mapreduce 完成分词统计工作.
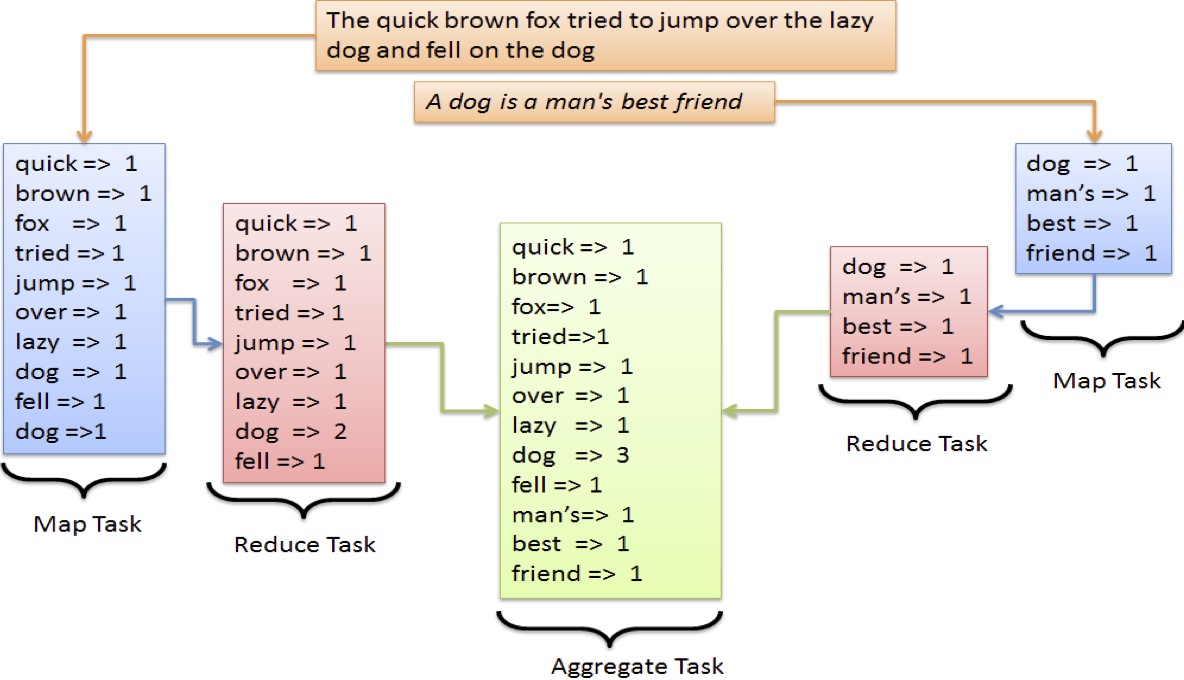
任务拆分:
Map Task:统计出句子中的单词.
Reduce Task:对map接过进行合并
Aggregate Task: 合并工作
设计如下:
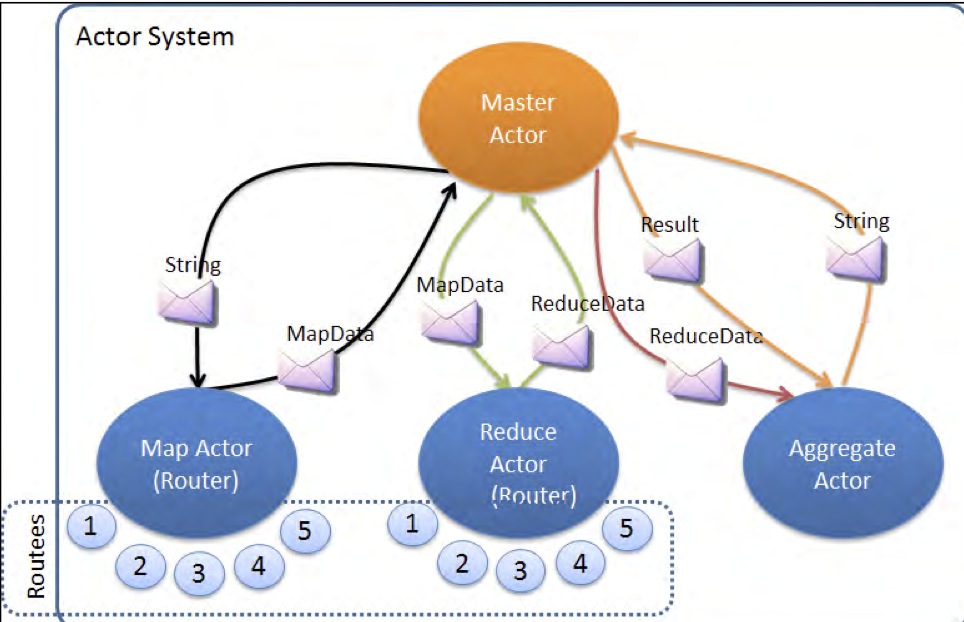
- Master Actor :将句子发送给Map Actor
- Map Actor : 统计数据,将结果回传,然后Master Actor将结果发送给Reduce Actor
- Reduce Actor : 合并数据, 将结果回传,然后Master Actor将结果发送给Aggregate Actor
- Aggregate Actor : 接受数据后更新内部状态,获取完整的数据列表.
- Master Acotr :往 Aggregate Actor发送信息,索要结果
MapActor
ActorRef mapActor = getContext().actorOf(Props.create(MapActor.class,reduceActor).withRouter(new RoundRobinPool(5)),"mapActor");
rounter的作用:
上面我们创建的MapActor,是一个Rounter Actor,执行withRount方法的时候,其实创建了多个相似的一组Actor实例,called rountes,这样可以通过多个Actor分散负载。
如果Actor是有状态的,多个实例可能就会有问题。
unhandled(message)
将发布事件到Actor系统的事件流中去。(ActorSystem's EventStream.)。与死信不同,actor终止或者无人接收时会发到死信队列。
一个actor可以在事件流中订阅类akka.actor.DeadLetter。
问题
- unhandle 后续处理,作用
- 如何接收死信
例子
有一个基于mapreduce的例子,实现了分词统计的功能。
参阅:MapReduceApplication